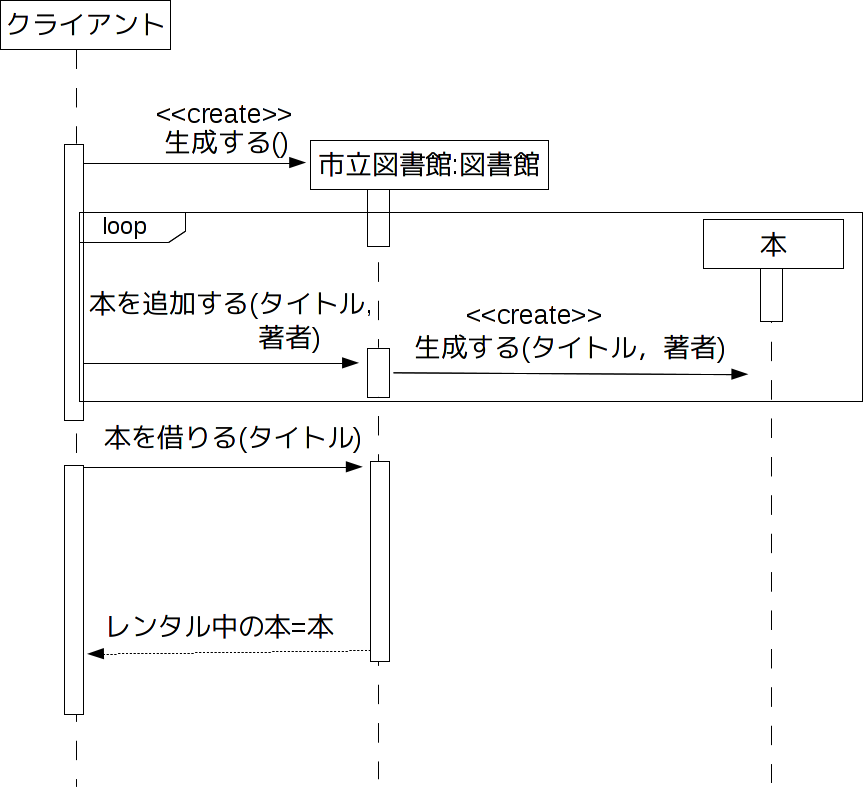
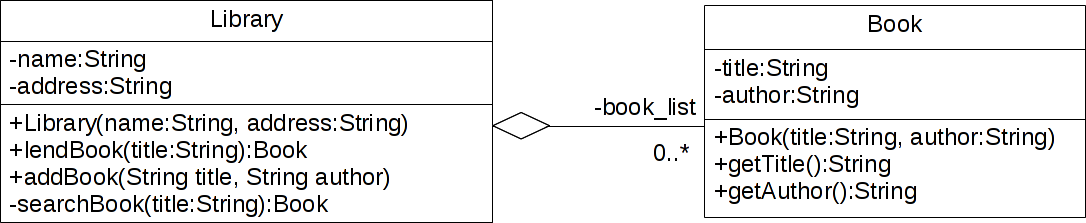
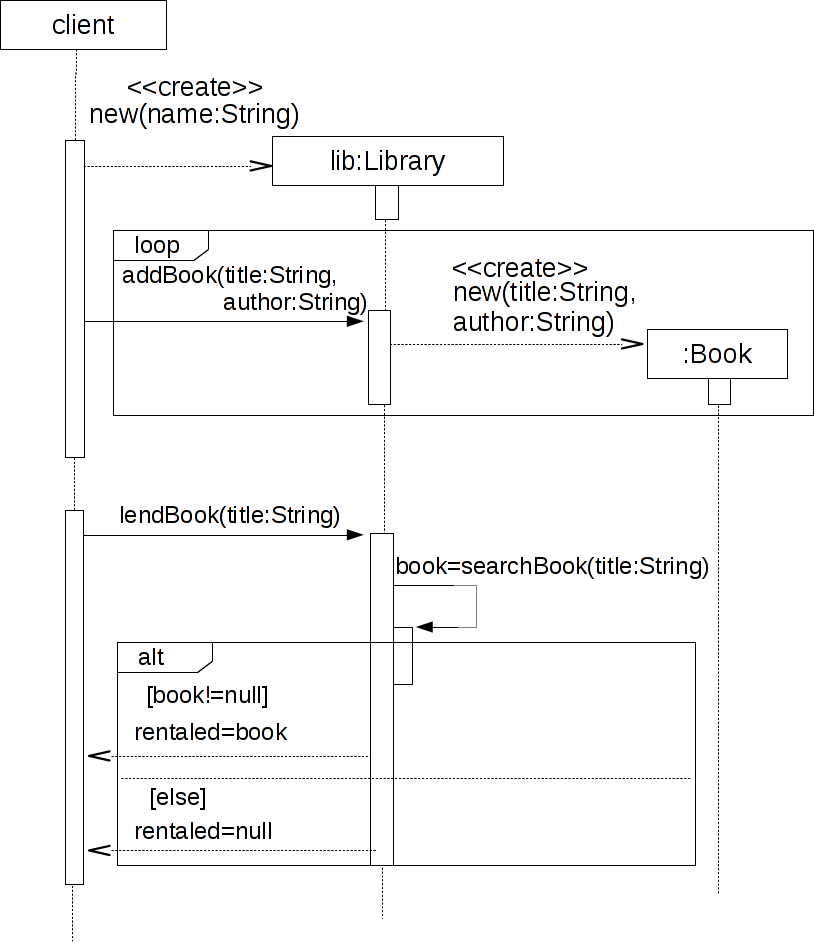
Pythonはクラス定義や継承、多重定義をサポートする。クラス定義の文法は、大雑把に説明すると次の通りである。
なおPythonではインデントでブロックを表すため、空のクラスや関数を定義する場合、pass文を使用する。
class Hoge: pass
pass文とは何もしない。
メンバ関数はクラスに属する関数である。メンバ関数の定義はC++の演算子の定義と似ている。C++は演算子の多重定義をメンバで行う際次のように行う。
class T
{
public:
void operator+(int arg2){ printf("%d\n", arg2); }
};
これは一見すると1つの引数しか取らないが、2つの引数を受け取る2項演算子である。Pythonのメンバ関数の定義はこれとよく似ている。Pythonでは、メンバ関数を定義する場合、第一引数にオブジェクトを受け取る変数を明示的に記述しなければならない。そして呼び出しの際は第二引数以降が1つずつずれる。
class Cls:
def setAdd(self, addee, adder):
self.ans = addee + adder
c = Cls()
c.set(1, 3)
第一引数の変数名は言語的な制約はない。
>>> class Hoge:
... def func1(hogefugapiyo):
... hogefugapiyo.v = 20
... def func2(hahaha):
... print(hahaha.v)
しかしselfという名前を用いることが多いようである。
インスタンス変数にアクセスする場合、例のように第1引数を使用してアクセスする。
Pythonではコンストラクタとデストラクタは次のように定義する。
class Hoge:
def __init__(self): # コンストラクタ
pass
def __del__(self): # デストラクタ
pass
コンストラクタとデストラクタは共に省略可能である。
C++ではdelete文で、Pythonではdel文でオブジェクトの削除を行うが、その振る舞いは異なる。C++のdelete文は、指定したアドレスに格納されたオブジェクトを削除し、そのデストラクタを呼び出す。これに対し、Pythonのdel文は参照カウントを1減らし、参照カウントが0になった時に同様の処理が行われる。
Pythonでは、基底クラスのコンストラクタ(__init__)は自動で呼び出されない。
Pythonには__init__とは別にインスタンスを生成する際に呼び出される関数がある。それが__new__である。__new__は静的メソッドで、新しいインスタンスを生成する際に自動的に呼び出される。__init__の第1引数がインスタンスであるのに対し、__new__にはクラスが与えられる。__new__()がclsのインスタンスを返さない限り、インスタンスの__init__は呼び出されない。なお__init__と__new__の第2引数以降は同じものが与えられる。
class Hoge:
def __new__(cls):
print("new Parent")
return super().__new__(cls)
def __init__(self):
print("init Parent")
このクラスを利用した例は次の通りとなる。
>>> h = Hoge()
new Parent
init Parent
__new__は変更不能な型 (int, str, tuple など) のサブクラスでインスタンス生成をカスタマイズするために使用される。それゆえ、基本的に__new__をオーバーライドする必要はない。
C++ではクラス変数とクラス関数はそれぞれ次のようにstaticキーワードを使って表現する。この時、クラス関数の宣言と定義を分ける場合、定義ではstaticを記述しない。また、C++ではクラス変数はグローバル変数の一種であり、外部にstaticなしの定義を記述しなければならない。
#include
class Hoge {
private:
static int i; // クラス変数
static int get(); // (1) 宣言だけ記述し、定義は外で記述
public:
static void set(int v) // (2) まとめて書く
{
i = v;
}
};
int Hoge::i; // 必須
int Hoge::get()
{
return i;
}
int main()
{
Hoge v1, v2;
v1.set(10);
std::cout << v2.get() << std::endl;
return 0;
}
これに対し、Pythonでは、特殊な関数やクラスの定義にはデコレータという機能を使用する。デコレータは定義するクラスや関数に機能の追加や変更を施す。クラス関数を定義する場合、関数デコレータのclassmethodを使用する。
class Hoge:
@classmethod
def set(cls, v):
cls.__v = v
@classmethod
def get(self):
return cls.__v
以下に実行例を示す。
>>> o1, o2 = Hoge(), Hoge()
>>> o1.set(1)
>>> o2.get()
1
なおデコレータの定義については本稿では言及しない。以前の記事の
『Pythonの特徴』を参照されたし。
編集中
C++で多態化を実装するには、virtualキーワードを使用して関数をオーバーライドにする宣言が必要だった。これに対してPythonのメンバ関数は、標準ではメンバ関数が全てC++のpublicとvirtualな関数である。それゆえ、継承クラスで定義した同名の関数は自動的にオーバーライドされる。
Pythonでは継承は次のように記述する。
class クラス名[(基底クラス [, 基底クラス, ...])]:
以下に実際の例を示す。
class Parent:
def __func(self):
print("Hello, World")
class Child(Parent):
def func(self):
super().func()
PythonではC++と異なり、継承の際にアクセス指定を指定しない。また、基底クラスのコンストラクタ(__init__)は自動で呼び出されない。
静的な型チェックを行うC++では、コンパイル時に継承関係を考慮した型チェックが行われる。これに対し、Pythonではisinstanceという組み込み関数を使用して型チェックを行う。
>>> class Parent: pass
...
>>> class Child(Parent): pass
...
>>> p, c = Parent(), Child()
>>> isinstance(p, Parent)
True
>>> isinstance(c, Parent)
True
PythonはC++と同様多重継承が可能な仕様である。文法は以下の通りである。
しかしいくつかの振る舞いが異なる。例えば、継承の際C++にはアクセス指定子を指定してアクセス制御を行うが、Pythonにはそのような機能はない(publicな状態)。
C++やJava、C#などの多くの言語では、文法は違えどpublic、private、protectedというキーワードでメンバのアクセス制御を行う。
class Hoge:
v1 = 10 # クラス変数
_v2 = 100 # プライベートで使用する意図のクラス変数
__v3 = 1000 # プライベートクラス変数
def func1(self): # メンバ関数
print(self.v4) # インスタンス(オブジェクト)変数
print(self.__v5) # プライベートインスタンス変数
def __func2(self): # プライベートメンバ関数
pass
@classmethod
def func3(cls): # クラス関数
print(cls.v1) # クラス変数
C++ではメンバ関数の標準のアクセス状態は"private"であるが、Pythonでは"virtual public"である。
Pythonでメンバをプライベートとする場合、以下のように接頭辞が__から始まる名前にする。
class Hoge:
def __func(self):
print("Hello")
このプライベートメンバにアクセスしようとすると次のようにAttributeErrorが送出される。
>>> Hoge().__func()
AttributeError: Hoge instance has no attribute '__func'
Pythonでは、プライベートメンバの名前は、外部から参照できなくなっている訳ではなく、自動的に名前を変更される。これにより継承クラスで名前の競合を防いでいる。なおプライベートメンバの変更後の名前は、プライベートメンバの名前の接頭に「_クラス名」を追加したものである。前述のサンプルコードのHogeの名前空間を閲覧した結果を以下に示す。
>>> dir(Hoge)
['_Hoge__func', '__class__', '__delattr__', '__dict__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__gt__',
'__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__sizeof__', '__str__', '__subclasshook__', '__weakref__']
このように名前が変更されただけであるため、実はこのようにアクセスすることが可能である。
>>> h = Hoge()
>>> h._Hoge__func()
Hello
多様性
検索順
- D
- B
- C
- A
class A:
def func(self):
print("I am A\n")
class B(A):
def func(self):
print("I am B\n")
class C(A):
def func(self):
print("I am C\n")
class D(B, C): pass
C++の変数は、スコープやライフタイム、ストレージクラス、アクセス制御、修飾子などの組合せによって非常にさまざまなものがある。Pythonの変数はC++程の種類はないが、それでもいくつかの種類がある。以下にC++の定義と比較した場合のPythonの変数定義を紹介する。
編集中
特殊関数
編集中
Pythonではtry文を次のように記述する。
try:
// 例外が発生しうる処理
except Exception:
// 例外取得と処理
else:
// try節が末尾までいった場合の処理
finally:
// 最後に必ず行われる処理
Pythonではcatch節の代わりにexcept節がある。except節は送出された例外オブジェクトをasで指定した名前に束縛することができる。
except節には、BaseExceptionのサブクラスを指定できる。しかし通常独自の例外を定義する場合、ExceptionというBaseExceptionのサブクラスを継承する。
また、tryとexcept節以外にもelse節とfinally節がある。else節を記述した場合、制御がtry節の末尾までいった場合に実行される。これに対し、finally節を記述した場合、どの節を処理したかに関わらず必ず最後に呼び出される。except節とelse節、finally節は省略可能であり、except節は複数記述でいる。ただし、except節とfinally節の両方を省略することはできない。